


Large-scale language models (LLMs) demonstrate proficiency in solving complex problems across mathematics, scientific research and software engineering. Before you reach a conclusion, the Chain of Thinking (COT) prompt is crucial in guiding the model through intermediate inference steps. Rehnection Learning (RL) is another important component that enables structured inference, allowing models to efficiently recognize and correct errors. Despite these advances, challenges remain to extend COT length while maintaining accuracy, especially in specialized domains where structured inference is important.
An important problem in improving LLMS reasoning abilities is the creation of a long, structured thinking chain. Existing models are fighting high multiple tasks that require iterative reasoning, such as PHD-level scientific problem solving and competitive mathematics. Simply scaling of model size and training data does not guarantee improvements to COT functionality. Furthermore, RL-based training requires accurate reward shapes as inappropriate reward mechanisms can lead to counter-effective learning behaviors. The aim of this study is to identify the fundamental factors that influence the emergence of COTs to stabilize and improve long chain inference and design optimal training strategies.
Previously, researchers had adopted monitored fine-tuning (SFT) and reinforcement learning to enhance COT inference in LLMS. SFT is commonly used to initialize models using structured inference examples, while RL is applied to extend the fine-tuning and inference functionality. However, traditional RL approaches lack stability when increasing the length of COT, leading to inconsistent quality of inference. Verifiable reward signals such as the accuracy of ground truths are important to prevent the model from engaging in reward hacking. Here, we learn how to optimize rewards without the model really improving inference performance. Despite these efforts, current training methodologies lack a systematic approach to effectively scaling and stabilizing long COTS.
Researchers at Carnegie Mellon University and In.AI have introduced a comprehensive framework for analyzing and optimizing LLMS long COT inference. Their approach focused on determining the mechanisms underlying long chain inference and experimenting with different training methods to assess their impact. The team systematically tested SFT and RL techniques, highlighting the importance of structured reward shapes. A new cosine length scaling reward with repeated penalties has been developed so that the model improves inference strategies such as branching and backtracking, leading to a more effective problem-solving process. Furthermore, researchers have investigated the incorporation of web extraction solutions as verifiable reward signals to enhance learning processes, particularly for distributed emission (OOD) tasks such as STEM problem solving.
The training methodology included extensive experiments on a variety of basic models, including Llama-3.1-8B and QWEN2.5-7B-MATH, each representing general-purpose and mathematical specialist models, respectively. Researchers used a dataset of 7,500 training sample prompts from mathematics to ensure access to a verifiable ground truth solution. Initial training in SFT provided the basis for long COT development, followed by RL optimization. To compare the generated responses with the correct answers, a rule-based validation agent was employed to ensure stability in the learning process. The team introduced a repetitive penalty mechanism to block the model from generating redundant inference paths and further improve the shape of the rewards, encouraging efficient problem solving. The team also analyzed data extracted from the web corpus and evaluated the potential for noisy but diverse supervisory signals in purifying cot length scaling.

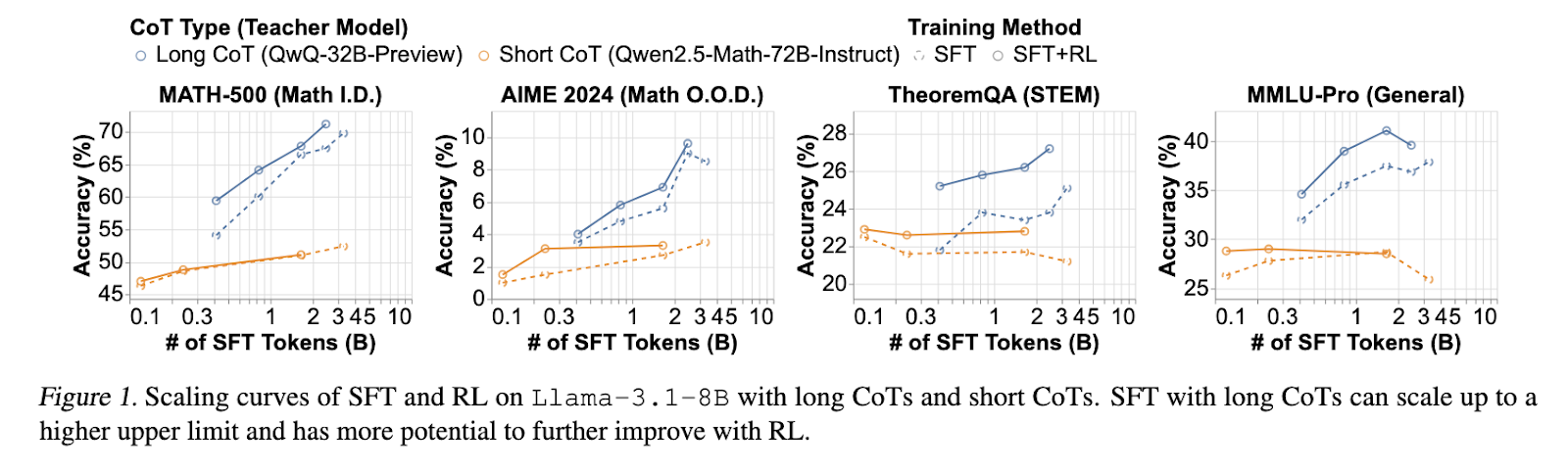
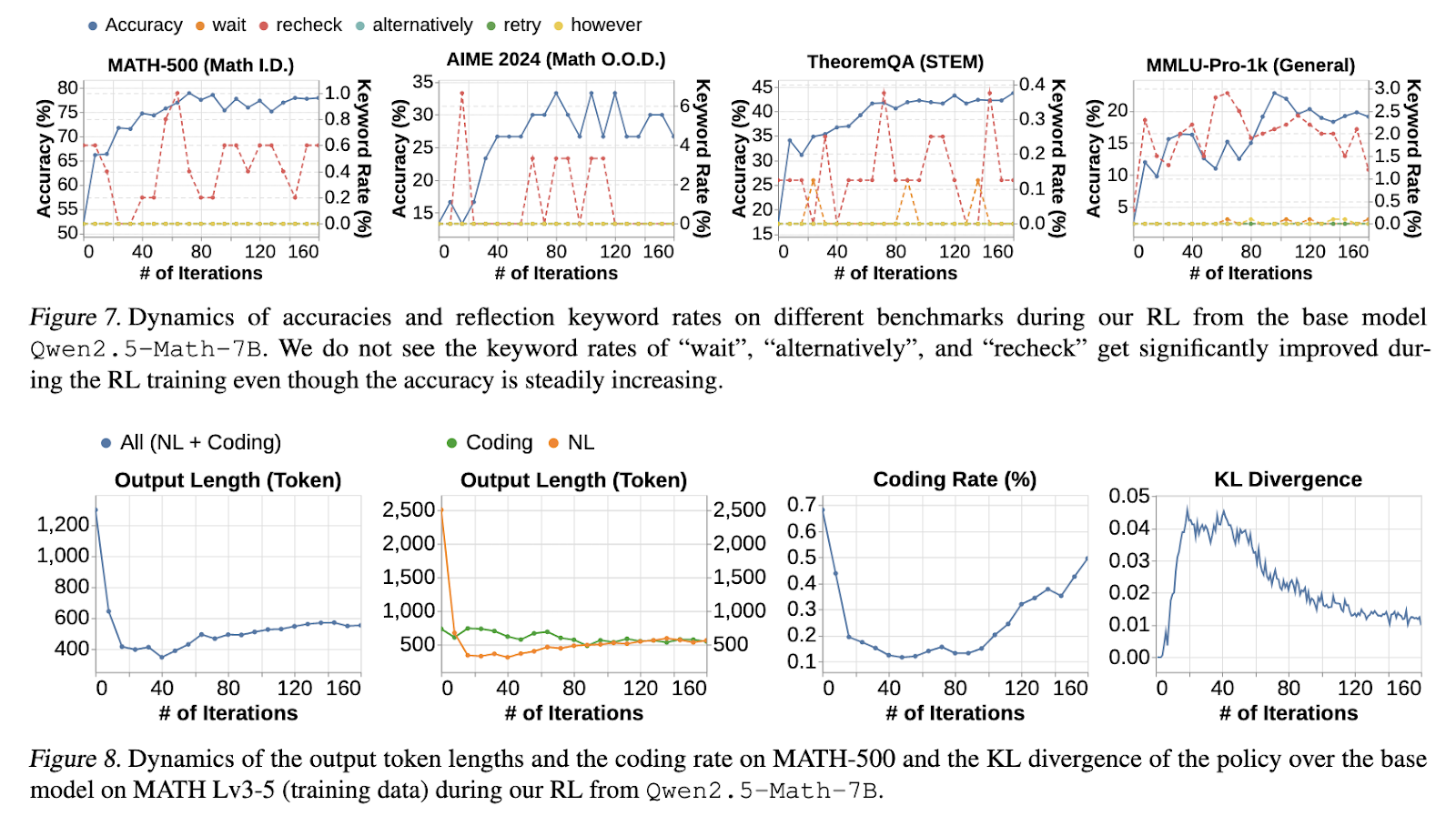
The findings revealed some important insights into long COT reasoning. Models trained with long COT SFTs achieved consistently better accuracy than models initialized with short COT SFTs. The MATH-500 benchmark showed significant improvements in the long COT SFT model, with accuracy above 70% and the short COT SFT model below 55%. RL fine-tuning further strengthened the long COT model, providing an additional 3% absolute accuracy gain. The introduction of rewards to scale the length of Cosine was effective in stabilizing the trajectory of inference, preventing the growth of over- or unstructured COTs. Furthermore, models incorporating filtered web extraction solutions demonstrated improved generalization capabilities, with 15-50% accuracy increase recorded, especially in OOD benchmarks such as AIME 2024 and Theoremqa. The study also confirmed that core inference skills such as error verification and correction are essentially present in the basic model. Still, effective RL training is required to effectively strengthen these abilities.
This study has significantly advanced the understanding and optimization of LLMS long COT inference. Researchers successfully identify key training factors that reinforce structured reasoning, highlighting the importance of monitored fine-tuning, verifiable reward signals, and highlighting carefully designed reinforcement learning techniques. I did. The findings highlight the possibilities for further research in improving RL methodologies, optimizing reward formation mechanisms, and leveraging the use of a variety of data sources to enhance model inference capabilities. The contributions of this research provide valuable insight into the future development of AI models with robust, interpretable, scalable inference capabilities.
Check out the paper. All credits for this study will be directed to researchers in this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn groups. Don’t forget to join the 75k+ ml subreddit.
Commended open source AI platform recommended: “Intelagent is an open source multi-agent framework for evaluating complex conversational AI systems” (promotion)
Nikhil is an intern consultant at MarktechPost. He pursues an integrated dual degree in materials at Haragpur, Indian Institute of Technology. Nikhil is an AI/ML enthusiast and constantly researches applications in fields such as biomaterials and biomedicine. With a strong background in material science, he creates opportunities to explore and contribute to new advancements.
✅ (Recommended) Join the Telegram Channel