


Google Gemini was first launched in December 2023, but recently underwent a major upgrade with the release of Gemini 2.0 in early December. It’s built for what Google calls the “age of agents,” with the ability to run complex, multi-step processes more independently.
Other key improvements include native image and audio processing, faster response times, improved coding capabilities, and other Google apps being developed to power your Android smartphone, computer, and other connected devices. and new integrations with solutions.
related
5 easy ways to supercharge your Android with Google Gemini
Google Assistant Killer?
A dizzying onslaught of new Gemini models
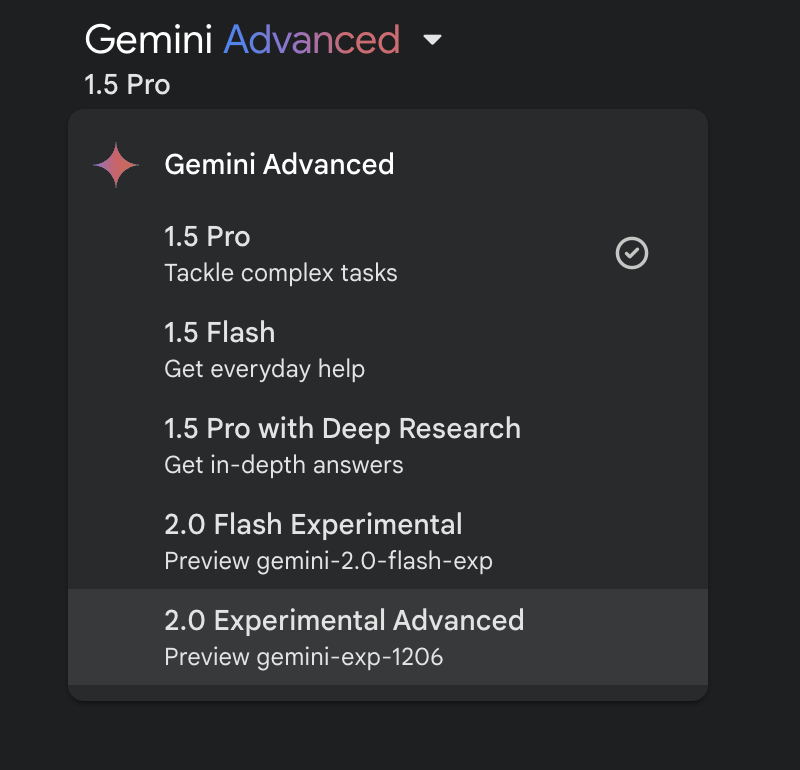
Google has been developing a ton of different AI models lately, with multiple new versions released in the past few weeks. 2.0 Improvements in certain areas, such as Flash speed, are immediately noticeable. Some go into more specialized fields, such as coding. 2.0 Pro, on the other hand, is still in development.
The new 2.0 model is available on desktop and recently on the Gemini mobile app, where there is a selector to select the model. And let’s not forget the on-device Nano model. This already powers certain Google Pixel features such as call summarization. It is also worth noting that in recent days another new model 2.0 Experimental Advanced has appeared on the desktop.
But as Taylor Kearns points out, Gemini is becoming increasingly complex, making it difficult to keep track of all its variants. There isn’t much information available about Experimental Advanced, so I’m sticking to the two in the comparison below.
Features Gemini 1.5 Pro Gemini 2.0 Flash Experimental Context Window 1 million tokens (approximately 750,000 words or 1,500 pages of text) 1 million tokens (approximately 750,000 words or 1,500 pages of text) Speed Response within seconds approximately 2x faster Power Consumption High Low Reasoning/Logic Powerful reasoning and collaboration It claims that inference is improved and agent capabilities are added for multimodal processing by converting images and audio to text. Native image and audio processing. You can now “speak” using AI voice. Image creation has been paused Supported Coding Can generate code Can generate and run code, parse API responses, and integrate data into external applications
Gemini 2.0 Flash is all about speed and efficiency

Source: Google
As the name suggests, Gemini 2.0 flash is designed for speed. Google claims it’s twice as fast as the previous version. As a user of both 1.5 Pro and 2.0 Flash Experimental, I can attest to its agility.
2.0 provides near-instantaneous responses to the same queries that could take seconds in 1.5 Pro. This may not sound like a big impact, but instantaneous responses unlock new possibilities for real-time applications such as voice interaction. It also makes the overall user experience feel more polished. Despite its increased power, Gemini 2.0 flash is designed to be more energy efficient, which can directly translate into improved battery life for your smartphone.
Gemini 2.0 Flash brings enhancements to other core areas. Google says it performs better than the Gemini 1.5 Pro on complex tasks like coding, math, and logical reasoning. Additionally, Gemini 2.0 Flash can now directly execute code, autonomously process API responses, and call user-defined functions. 2.0 is starting to look more like an end-to-end development solution than a simple code generator.
Gemini wants to be your AI agent
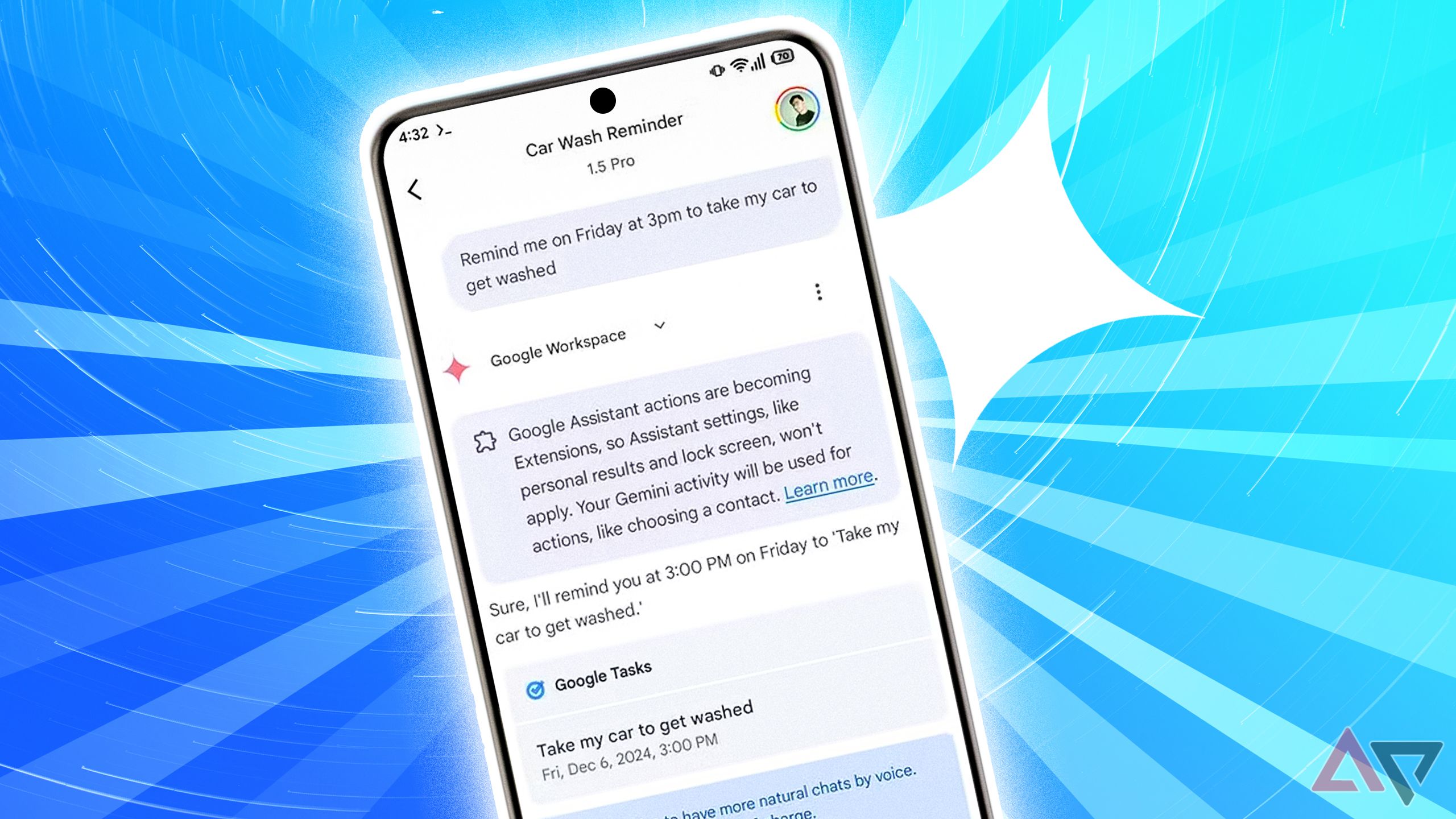
Agentic AI brings Gemini to proactive assistance. This means that Gemini can act as an agent and perform multi-step tasks on your behalf. Future applications will include everything from gaming and robotics to travel planning.
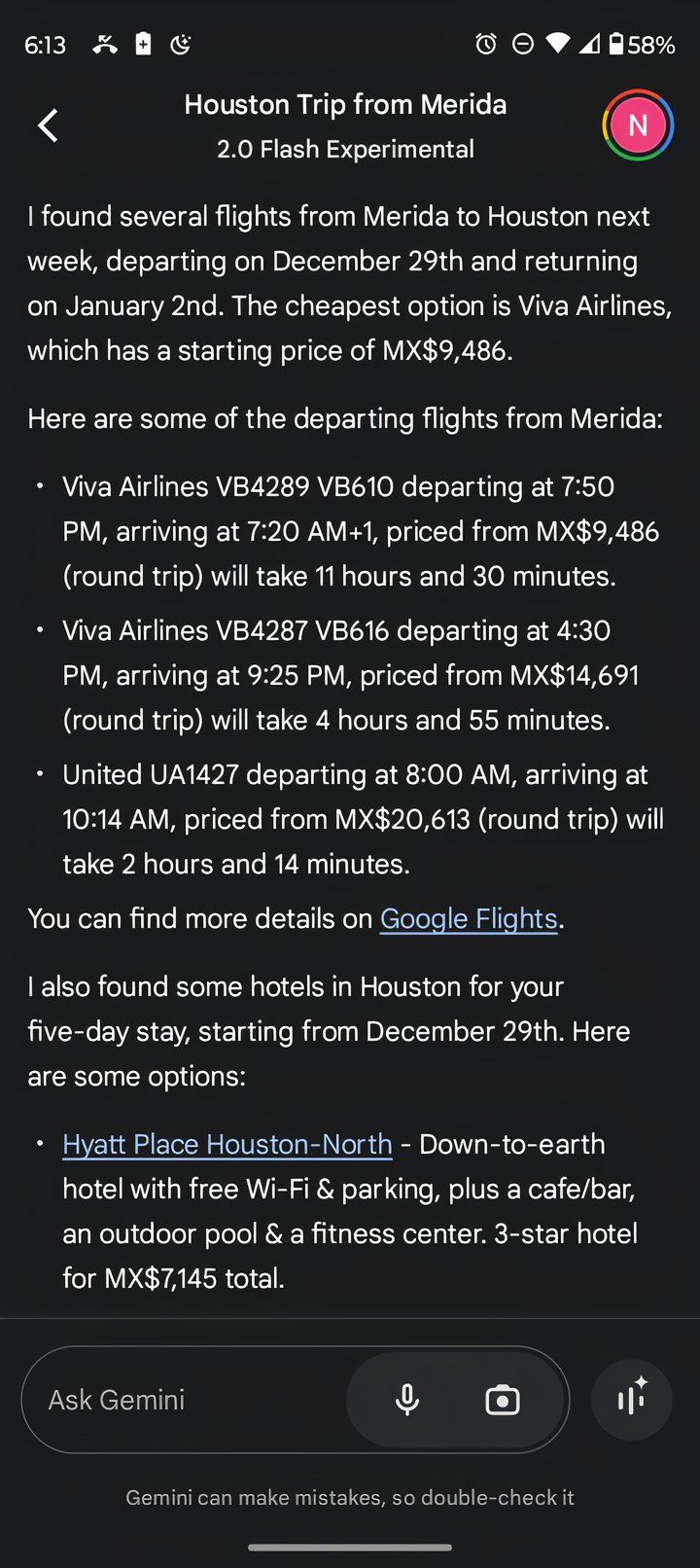
Suppose you are planning a trip to Tokyo. Instead of just asking your Gemini for sightseeing suggestions, you can ask them, “Create me a detailed itinerary for a 5-day trip to Tokyo, including must-see attractions, recommended local restaurants, and estimated costs.” Probably. I tried this exact prompt and the platform generated an attractive daily itinerary for me. However, there are still missing components.
In theory, Gemini can do much more, such as booking flights, accommodation, and reserving a table at a restaurant. In fact, 2.0 Flash integrates with Google Flights and can display hotel availability at your destination, but the final step to automate the entire process is still to come. It’s easy to see how this can be a difficult problem, as booking the wrong flight, for example, can literally cost you a lot of money. Imagine an AI booking the wrong trip to Springfield.
Gemini 2.0 can see, hear and speak
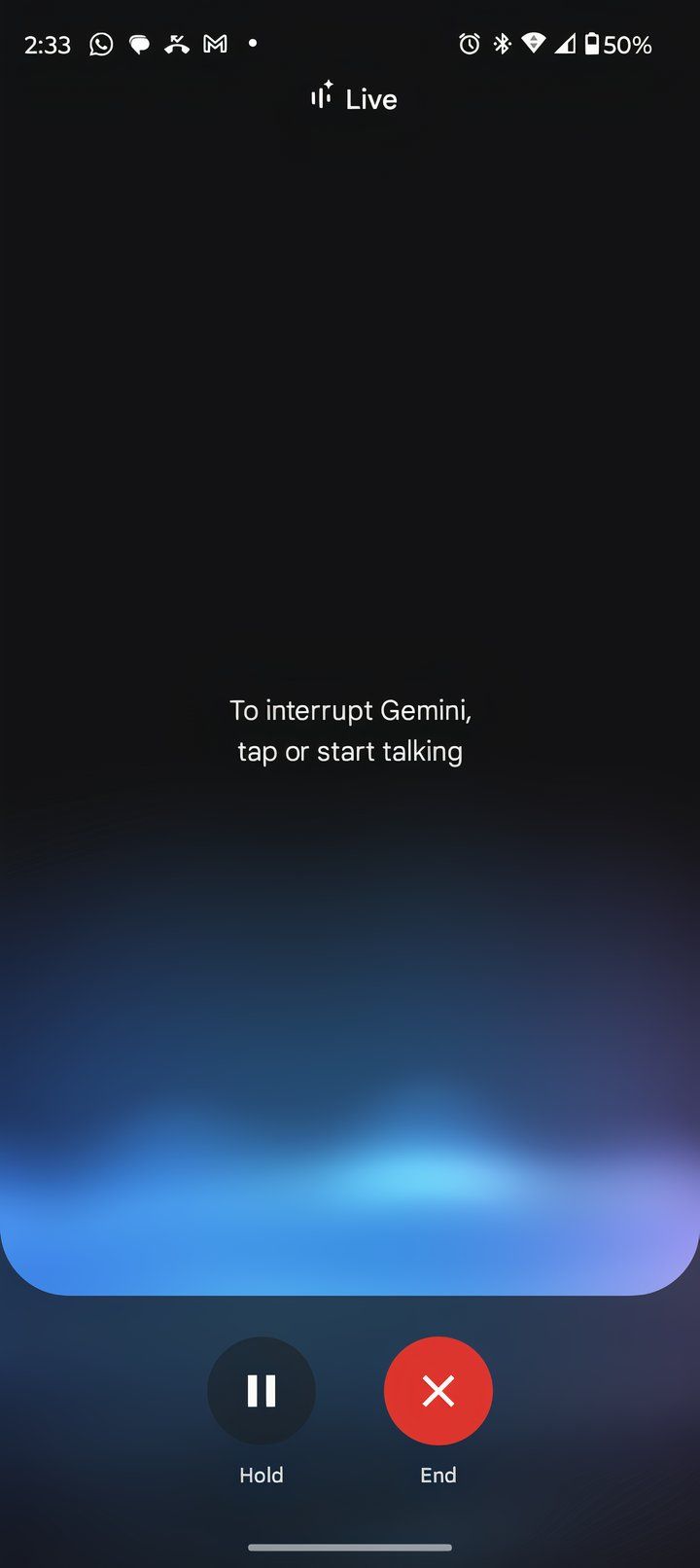
Multimodal input/output advances within Gemini 2.0 are another important feature. By seamlessly integrating information from various sources such as text, images, video, and audio, Gemini 2.0 can experience the world as we do. This paves the way for more human-like communication.
With Gemini 2.0, you can now have conversations using AI voices. The mobile app had several different voices to choose from, and I had a surprisingly natural and fluid conversation where I selected my favorite and asked the AI questions about the city I wanted to visit. The level of effort is clearly lower than typing a query and reading the response. While this feature is not new to the industry (think AI “companion” apps), it is new to Gemini.
Native image and audio processing provides noticeable improvements
A great improvement in Gemini 2.0 is the ability to process images and audio directly. In contrast, previous versions converted these inputs to text, which lost more information. Direct processing allows for a deeper understanding of the input. Gemini 2.0 can not only identify elements in images and audio, but also understand their relationships to each other and the scene as a whole.
During my test, I took an image looking out from my office and sent it to Gemini 2.0 Flash. There is a window screen in the foreground, and shrubs and other objects in the midground. The AI quickly recognized that the photo was taken through a screen and detailed other elements in the scene. Overall, we found that the 2.0 model provided more nuanced and detailed image analysis than previous versions.
Gemini image production is back, but who cares?
Despite all the hype about Gemini 2.0’s improvements, the return of Imagen image generation was a bit boring. After the initial controversy and subsequent feature disabling due to bias and inaccuracy, the re-release felt uninteresting. Perhaps Imagen has been watered down to avoid further controversy, or perhaps the novelty of AI image generation has simply worn off during Google’s long hiatus.

The image above was created by Gemini 2.0 Flash Experimental when asked to create the most interesting image imaginable. I understand it’s a subjective prompt, but I can still say the results are underwhelming. At best, it looks like a scene from a video game.
After further experimentation, I asked 2.0 Flash Experimental to simply “create an image of a person” and it refused. When I went back to 1.5 Pro and saw the same prompt, I was greeted with a brightly colored stock photo-like image of a group of friends. Imagen allows you to see through the eyes of Google’s AI, but the perspective isn’t very exciting.
New integration portends the future

Source: Google
Google aims to provide a more unified user experience by incorporating Gemini functionality into core services such as Search, Maps, and Workspaces.
In the future, search queries on Google will generate dynamic AI-powered responses, leveraging information from emails, documents, and even location history to provide more personalized results. It will be like this. Google is already experimenting with AI search summaries that feature audio summaries in the style of its sister product, NotebookLM.
Early efforts like Project Astra and Project Mariner have finally seen the light of day with the latest Gemini models. Astra consists of experiments with AI-powered code agents such as Jules. Mariner, on the other hand, may enable tasks such as autofilling forms and summarizing web pages. These projects are essentially the philosophical pillars on which Google develops AI applications and services.

related
Google’s experimental Gemini 2.0 Advanced model is here, but it’s not for everyone
A free Pixel subscription may help
Google is building a strong AI foundation with Gemini
Gemini 2.0 is a significant step forward for Google AI, delivering faster speeds, enhanced inference, and seamless multimodal integration. The lackluster image generation and confusing model variations highlight the complexity of this rapidly changing category.
However, advances in agent AI, new coding, voice and image capabilities, and deeper integration with core Google services portend good things to come in 2025.