


The team at Novasky, “a collaborative initiative led by students and advisors from the Sky Computing Lab at the University of California, Berkeley,” has accomplished something that seemed impossible just a few months ago. They created a high-performance AI inference model that cost less than $450 to train.
Unlike traditional LLMs, which simply predict the next word in a sentence, so-called “reasoning models” understand a problem, analyze different approaches to solving it, and implement the optimal solution. It is designed to. This makes these models difficult to train and configure, as they not only have to predict the best response based on a training dataset, but also have to “reason” throughout the problem-solving process.
That’s why a subscription to ChatGPT Pro, which runs the latest O3 inference models, costs $200 per month. OpenAI claims that training and running these models is expensive.
The new Novasky model, called Sky-T1, corresponds to OpenAI’s first inference model, known as o1 (also known as Strawberry), which was released in September 2024 and costs users $20 per month. By comparison, Sky-T1 is a 32 billion parameter model that can only be run locally on your home computer if you have a powerful 24 GB GPU, such as the RTX 4090 or the older 3090 Ti. And it’s free.
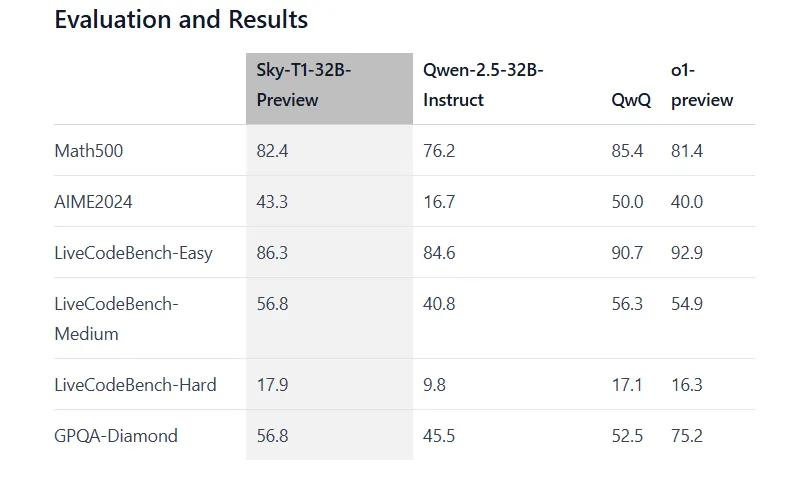
We’re not talking about watered down versions. Sky-T1-32B-Preview achieved 43.3% accuracy on AIME2024 math problems, outperforming OpenAI o1’s 40%. It received a score of 56.8% on LiveCodeBench-Medium compared to 54.9% on o1-preview. The model maintained good performance on other benchmarks, reaching 82.4% on the Math500 problem and scoring 81.4% on o1-preview.
The timing couldn’t be more interesting. AI inference competition has been heating up recently. OpenAI’s o3 has garnered attention by outperforming humans on general intelligence benchmarks, sparking debate over whether we’re seeing early AGI or general artificial intelligence. Meanwhile, China’s Deepseek v3 made headlines last year for outperforming OpenAI’s o1 while using fewer resources and being open source.
🚀 Introducing DeepSeek-V3!
Biggest leap forward:
⚡ 60 tokens/second (3x faster than V2!)
💪 Enhanced features
🛠 API compatibility remains the same
🌍 Completely open source models and papers🐋1/n pic.twitter.com/p1dV9gJ2Sd
— DeepSeek (@deepseek_ai) December 26, 2024
But Berkeley’s approach is different. Rather than chasing raw power, the team focuses on making powerful inference models available to the masses as cheaply as possible, making them easy to fine-tune and use locally without expensive enterprise hardware. We built a model that can be run on a computer.
“Incredibly, Sky-T1-32B-Preview was trained for less than $450, demonstrating that high-level inference functionality can be reproduced affordably and efficiently. All code is open source. ,” Novasky said in an official blog post.
Currently, OpenAI does not provide free access to inference models, but it does provide free access to less sophisticated models.
The prospect of being able to fine-tune an inference model to achieve domain-specific excellence for less than $500 is particularly appealing to developers. This is because such specialized models can outperform more powerful general-purpose models in the domain of interest. This cost-effective specialization opens new possibilities for intensive applications across scientific disciplines.
The team trained the model in just 19 hours using Nvidia H100 GPUs, following what they called a “recipe” that most developers should be able to reproduce. Training data appears to be the biggest hit for AI challenges.
“Our final data includes 5K coding data from APP and TACO, and 10K math data from the AIME, MATH, and Olympiads subsets of the NuminaMATH dataset. Additionally, we have STILL- We maintain 1,000 scientific and puzzle data from 2,” Novasky said.
The dataset was diverse enough to allow the model to be flexible about different types of problems. Novasky used another open source inference AI model, QwQ-32B-Preview, to generate the data and fine-tune the Qwen2.5-32B-Instruct open source LLM. The result was a powerful new model with inference capabilities that later became the Sky-T1.
A key finding from the team’s research is that bigger is better when it comes to AI models. Experiments using smaller parameter versions of 7 billion and 14 billion showed only small benefits. The sweet spot turned out to be 32 billion parameters. Large enough to avoid repeating the output, but not so large as to be impractical.
If you want your own version of a model beyond OpenAI o1, you can download Sky-T1 at Hugging Face. If your GPU isn’t powerful enough, but you still want to try it out, there are quantized versions from 8-bit to 2-bit, so you can test the next best thing, sacrificing accuracy for speed. Potato PC.
Please be careful. The developers warn that such levels of quantization are “not recommended for most purposes.”
Edited by Andrew Hayward
Generally intelligent newsletter
A weekly AI journey told by Gen, a generative AI model.