


OpenAI has published an incident report detailing the cause of last week’s ChatGPT outage and what it is doing to prevent it from happening again. The outage began at 10:40 AM on December 26, 2024 and was largely resolved by 3:11 PM, with the exception of ChatGPT, which was 100% recovered by 6:20 PM.
The following services were affected:
ChatGPT Sora Video Creation API: Agent, Real-time Audio, Batch, DALL-E
Cause of OpenAI outage
The outage was caused by a failure in the cloud provider’s data center that affected the OpenAI database. Although databases are mirrored across regions, switching to a backup database required manual intervention on the part of the cloud provider to redirect operations to a backup datacenter in another region. Although manual intervention is cited as the method for remediating the failure, the size of the project is cited as the reason it took so long.
Failover is an automatic process for switching to a backup system in the event of a system failure. OpenAI announced that it is working to create infrastructure changes to better respond to future cloud database failures.
OpenAI explained:
“In the coming weeks, we will add a layer of indirection under our control between our applications and cloud databases, making our systems more resilient to extended outages in any region on any cloud provider. We are embarking on a large-scale infrastructure effort to do this.” This makes failover much faster. ”
ChatGPT critical outage
OpenAI said the ChatGPT outage was due to a database failure at a regional cloud provider, but the impact was global, as evidenced by user reports on social media from across Europe and North America.
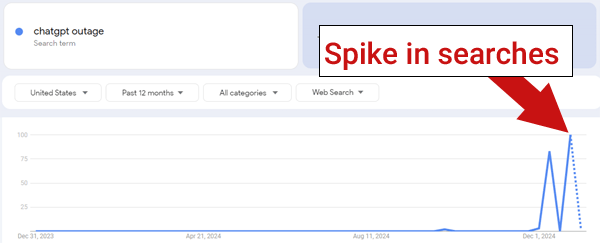
This may have been the largest event of its kind, according to Google Trends, which tracks search volume, and shows more people are searching for information about the event than in previous outages. has been.
Featured image by Shutterstock/lilgrapher