

Just a few days ago, OpenAI announced its latest o3 model which previewed some of its features. The new model’s surprising benchmark results have sparked a debate over its potential to be artificial general intelligence. While this is a huge leap forward in AI advancement, another AI model is making ripples throughout the AI community. DeepSeek-V3, a proprietary model from Chinese AI lab DeepSeek, is touted to be able to handle even the most advanced AI models, outperforming GPT-4o and Claude 3.5 Sonnet on various benchmarks. This model represents a future where innovation, low costs, and cutting-edge AI are no longer limited to a few tech giants.
DeepSeek-V3 has been hailed as the latest breakthrough in AI technology and highlights several high-tech innovations aimed at redefining AI applications. Andrej Karpathy, one of OpenAI’s founding members, said in a post about X that DeepSeek-V3 was trained with a significantly smaller budget and fewer resources than other frontier models. According to Tesla’s former AI director, leading models typically require clusters of 16,000 GPUs and massive computational resources, but the Chinese lab used just 2,048 GPUs and cost as little as $6 million. I trained for two months at Cost and achieved impressive results.
DeepSeek (a Chinese AI company) is making it look easy today with the open weight release of a frontier-grade LLM trained on a tongue-in-cheek budget (2048 GPUs in 2 months, $6 million).
For reference, this level of functionality is expected to require a cluster of nearly 16,000 GPUs. https://t.co/EW7q2pQ94B
— Andrei Karpathy (@karpathy) December 26, 2024
Here, we’ll take a closer look at what makes DeepSeek-V3: its architecture, features, pricing, benchmarks, and how it stacks up against other products.
What is DeepSeek-V3?
DeepSeek-V3 is a large-scale open source AI model trained on a budget of $5.5 million, compared to GPT-4o’s training cost of $100 million. This is an AI model that can be classified as a Mixture-of-Experts (MoE) language model. Essentially, the MoE model is like a team of expert models working together to answer your questions. Instead of one big model that handles everything, MoE has many “expert” models, each trained to excel at a specific task. The model reportedly has 671 billion parameters, but only 37 billion are active to handle a specific task. Experts say this selective activation allows the model to achieve high performance without using excessive computational resources.
DeepSeek-V3 is trained on 14.8 trillion tokens with a huge, high-quality dataset to provide a broader understanding of language and task-specific features. Additionally, this model uses several new techniques such as multi-head latent attention (MLA) and auxiliary lossless load balancing methods to increase training and deployment efficiency and reduce costs. These advances are new and allow DeepSeek-V3 to compete with some of today’s most advanced closed models.
This model is built with the NVIDIA H800 chip, a lower-performance but more cost-effective alternative to the H100 chip designed for restricted markets such as China. Despite its limitations, this model provides excellent results. DeepSeek-V3, with its innovative technology, is believed to be a major breakthrough in AI architecture and training efficiency. This model reportedly not only offers cutting-edge performance, but also achieves it with exceptional efficiency and scalability.
Function definition
As mentioned earlier, DeepSeek-V3 uses MLA to optimize memory usage and inference performance. According to reports, MoE models are known for poor performance, but DeepSeek-V3 minimizes this issue with its auxiliary lossless load balancing feature. These make this model an excellent choice for computationally intensive tasks. The entire process of training a model is more cost-effective due to reduced memory usage and faster computation. Additionally, DeepSeek-V3 can process up to 128,000 tokens in a single context, and this long context understanding gives it a competitive edge in areas such as legal document review and academic research.
The model also features multi-token prediction (MTP), allowing you to predict multiple words simultaneously, increasing token speed by up to 1.8x per second. It is important to note that traditional models predict one word at a time. Perhaps one of the biggest advantages of DeepSeek-V3 is its open source nature. This model provides researchers, developers, and businesses with unlimited access to its capabilities. Essentially, this gives smaller players access to high-performance AI tools, allowing them to compete with larger players.
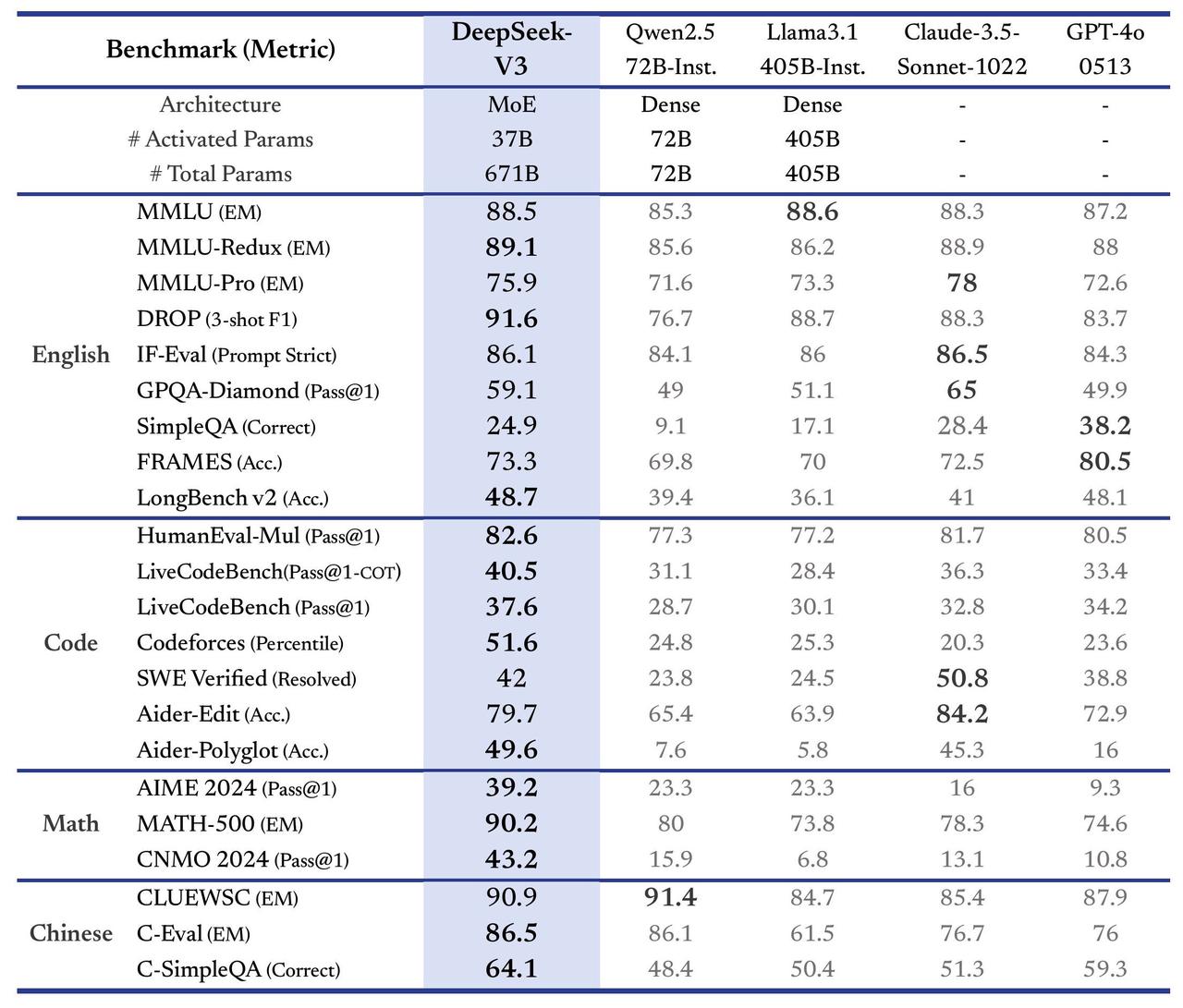 Benchmark performance of DeepSeek-V3.
Benchmark performance of DeepSeek-V3.
performance
In terms of performance, DeepSeek has compared this model to its peers (Claude-3.5, GPT-4o, Qwen2.5, Llama3.1, etc.) and shows exceptional performance across benchmarks. DeepSeek-V3 competes directly with established closed-source models such as OpenAI’s GPT-4o and Anthropic’s Claude 3.5 Sonnet, and outperforms them in several key areas. When it comes to math and coding, this model outperformed its competitors on benchmarks like MATH-500 and LiveCodeBench. This shows the model’s excellent problem-solving and programming abilities. Additionally, this model also excels at tasks that require understanding long texts. In the Chinese language task, this model showed exceptional strength.
In terms of limitations, DeepSeek-V3 can require large amounts of computational resources. Although faster than previous versions, the model’s real-time inference capabilities reportedly require further optimization. Some users also claimed that the focus on excelling in Chinese tasks affected their performance on English fact-based benchmarks.
big picture
The United States and China are at the forefront of an AI arms race. US export controls limit China’s access to advanced NVIDIA AI chips in an effort to thwart advances in AI. Now, with the innovation of DeepSeek-V3, the restriction may not have been as effective as intended. The model is completely open source, which also raises questions about the safety and impact of releasing powerful AI models to the public. The new model also signals a paradigm shift, making it possible to train powerful AI models without prohibitive investments. This shows how open source AI continues to challenge closed model developers like OpenAI and Anthropic.
DeepSeek-V3 models are available free of charge to developers, researchers, and businesses. It can be accessed via GitHub.
Discover the benefits of subscription!
Stay informed with access to our award-winning journalism.
Avoid misinformation with reliable, accurate reporting.
Make smarter decisions with key insights.
Choose your subscription package