


Human Robot Collaboration focuses on developing intelligent systems that work with humans in dynamic environments. Researchers aim to build robots that can understand and execute natural language instructions, but adapt to constraints such as spatial positioning, task sequences, and ability sharing between humans and machines. This field greatly improves robotics for home support, healthcare and industrial automation, where efficiency and adaptability are essential for seamless integration.
A key challenge in human-robot collaboration is the lack of comprehensive benchmarks for assessing planning and inference capabilities for multi-agent tasks. Previous models address the interaction of navigation and single agent, but are unable to capture the real-world complexity that robots must coordinate with humans. Many existing approaches do not consider real-time task tracking, partner adaptation, and effective error recovery. The lack of established standards makes it difficult to systematically evaluate and improve collaborative AI performance in interactive settings.
Current approaches of embodied AI often focus on performing single agent tasks, ignoring the need for coordination in multi-agent scenarios. Some methods rely on templated task instructions to limit scalability and task diversity, while others rely on manually created evaluation features to make large-scale assessments practical Not that. Despite advances, cutting-edge, large-scale language models (LLMS) struggle to track, coordinate, and recover from execution failures. These limitations hinder our ability to function efficiently in human-centric environments where adaptability and accurate task execution are essential.
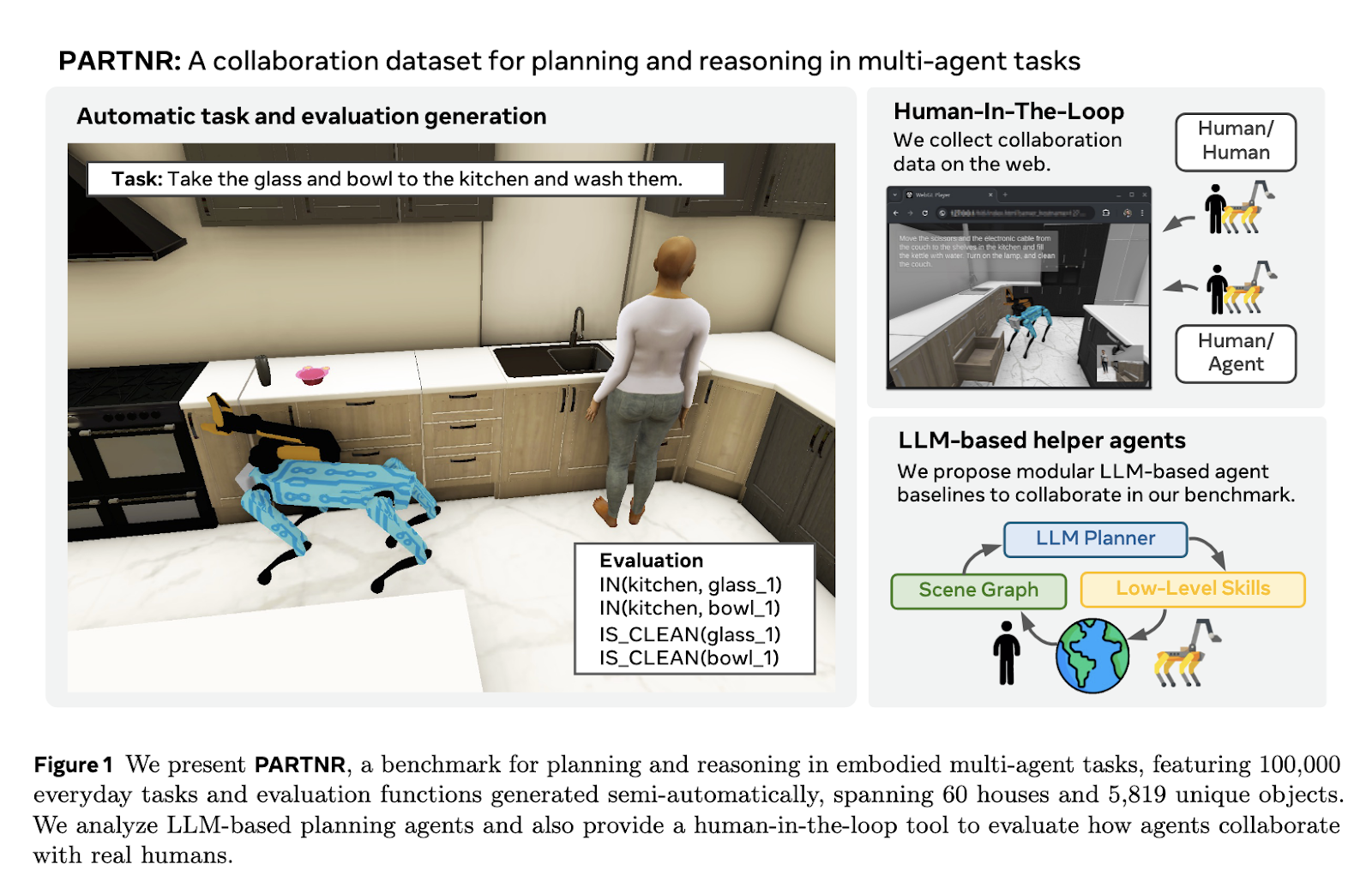
Fair Meta researchers have introduced PartNR (Planning and Inference Tasks for Human Robot Collaboration), a large-scale benchmark designed to evaluate human robot coordination in simulated environments. The PARTNR consists of 100,000 natural language tasks spanning 60 simulated homes and 5,819 unique objects. Benchmarks specifically evaluate tasks that incorporate spatial, temporal, and heterogeneous constraints. Researchers have ensured a realistic and scalable task generation process by leveraging semi-automated pipelines that integrate LLMS and simulations within loops. PARTNR aims to set standards for assessing AI’s ability to effectively collaborate with human partners.
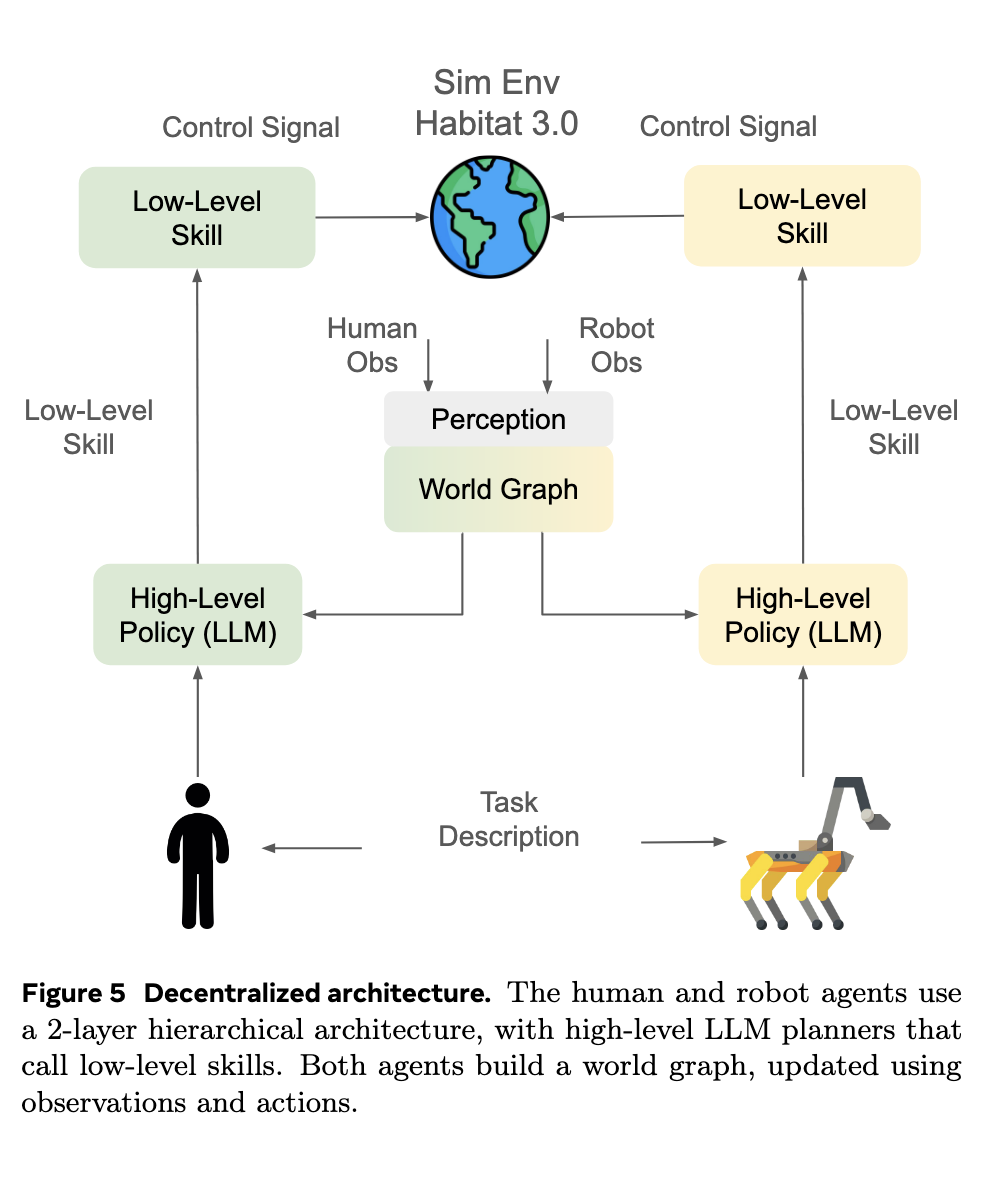
Researchers used LLM to generate task instruction and evaluation features and create benchmarks. I then filtered these through simulations to remove unexecutable tasks. The final dataset was subjected to human loop validation to increase task diversity and ensure accuracy. PARTNR tasks fall into four categories: unconstrained, spatial, temporal and heterogeneous. Unconstrained tasks allow for flexibility in the order of execution, and spatial tasks require the positioning of specific objects. Temporary tasks require ordered execution, while heterogeneous tasks involve actions beyond the robot’s capabilities and require human intervention. These task structures pose challenges to the accuracy of coordination, tracking and execution.
Evaluation of LLM-based planning agents in PARTNR revealed significant limitations in coordination, task tracking, and error recovery. When paired with humans, LLM guided robots required 1.5 times more steps than human teams and 1.1 times more steps than a single human to complete the task. The success rate of cutting-edge LLMS was only 30% under non-conditional conditions compared to 93% when tasks were performed by humans alone. Furthermore, the tweaked smaller LLM achieved performance comparable to models, while being 8.6 times faster inference. In a distributed multi-agent configuration, task completion required 1.3 times the steps of a single agent scenario, indicating the inefficiency of the current coordination mechanism.
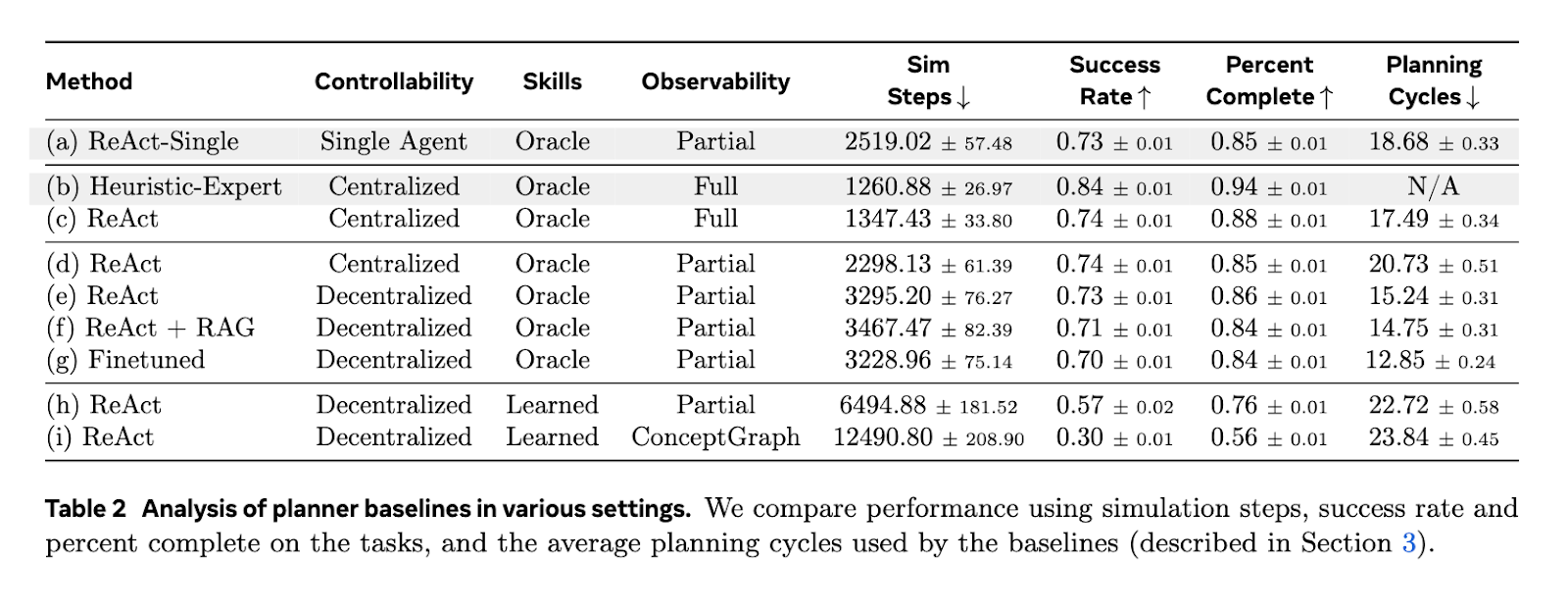
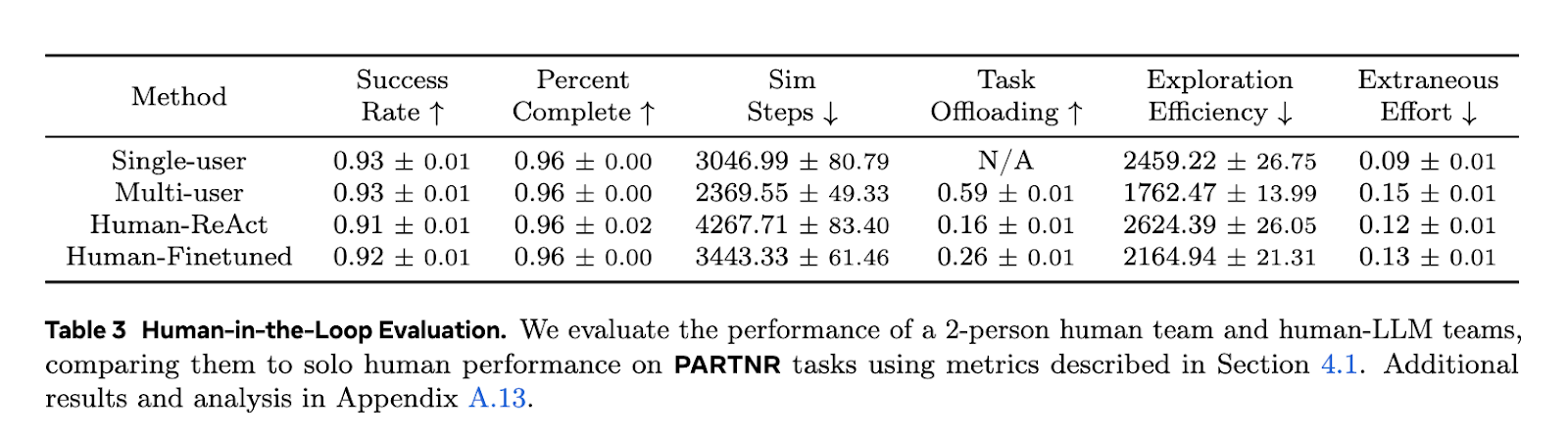
PARTNR highlights key gaps in existing AI-driven human robot collaboration models, highlighting better planning, tracking and decision-making strategies. The findings show that despite advances in AI, the collaboration benchmark between humans and robots requires substantial improvements to close the gap between AI models and human performance. The structured evaluation framework provided by PARTNR provides a pathway to advance AI’s ability to efficiently collaborate, plan, and execute tasks. Future research should focus on improving LLM-based planners, improving coordination mechanisms, and enhancing perceptual models to address current limitations of multi-agent interactions. PARTNR is a valuable resource to drive innovation in collaborative AI systems.
Check out the paper. All credits for this study will be sent to researchers in this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn groups. Don’t forget to join the 75k+ ml subreddit.
Commended open source AI platform recommended: “Intelagent is an open source multi-agent framework for evaluating complex conversational AI systems” (promotion)
Nikhil is an intern consultant at MarktechPost. He pursues an integrated dual degree in materials at Haragpur, Indian Institute of Technology. Nikhil is an AI/ML enthusiast and constantly researches applications in fields such as biomaterials and biomedicine. With a strong background in material science, he creates opportunities to explore and contribute to new advancements.
✅ (Recommended) Join the Telegram Channel