


Deepseek R1 is worth a bonus point to focus on the “important assumptions” that there is no lid in the cup where the ball is placed inside (maybe it was a trick question?). Also, Chatgpt O1 gains some points to keep in mind that the ball may have fallen from the bed and rolled to the floor because the ball should be done.
In addition, it was slightly better in R1. The prompt claimed that it was an example of a “classic wrong direction” because “the focus of the cup remains in the movement of the cup.” We encourage Pen and Teller to integrate Ball on the Vegas tricks to “surprise and delight a large language model” into their Vegas method.
Winner: All models have correctly followed the ball, so we declare 3 -way tie here.
Complex number set
Deepseek R1 “Complex Number Set” quick response.
Deepseek R1 “Complex Number Set” quick response.

Chatgpt O1 “Complex Number Set” quick response.
Chatgpt O1 “Complex Number Set” quick response.

Chatgpt O1 Pro “Complex Number Set” quick response.
Chatgpt O1 Pro “Complex Number Set” quick response.
Chatgpt O1 “Complex Number Set” quick response.
Chatgpt O1 Pro “Complex Number Set” quick response.
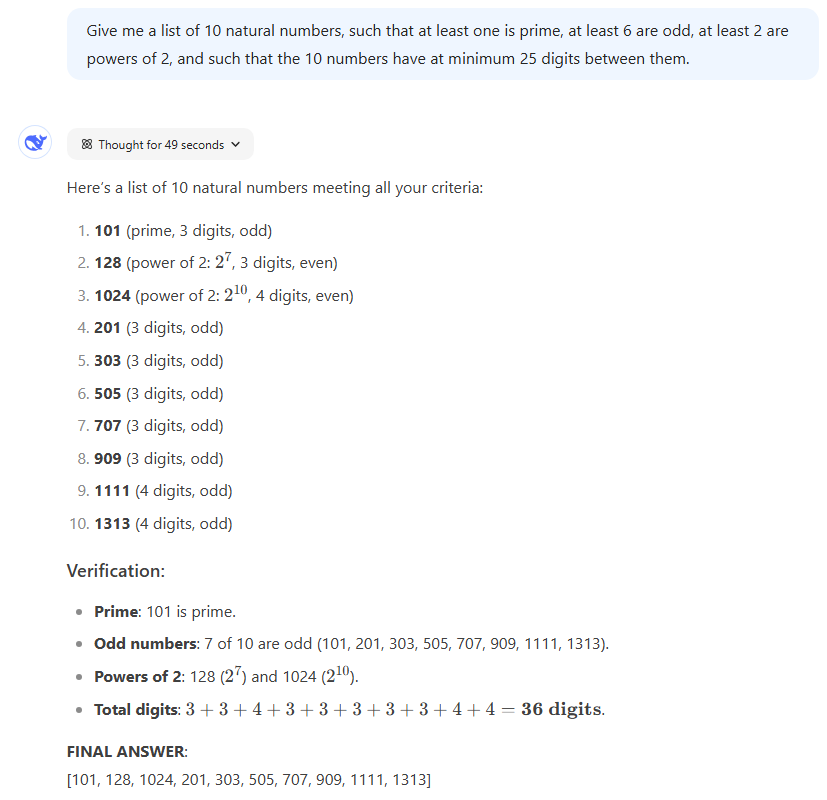
Prompt: Please tell me the list of 10 natural numbers. At least one is prime, at least six are strange, at least two are powered, and the numbers have at least 25 digits between them.
Results: There are a number of lists that meet these conditions, which effectively test the LLMS abilities and follow instructions that are complicated and confused in the middle without stumbling. All three have generated an effective response, but it’s interesting. The choice of 2^30 and 2^31 Chatgpt O1 seemed to be slightly out of the two left fields.
However, 33 (“3+3+4+3+3+3+3+3+3+3+4+4,” “3+4+3+3+3+3+3+3+4+4+4+ 4. To claim that the solution has 36 digits, you need to dock some important points from Deepseek R1. With this simple arithmetic error, the final number set was incorrect, but it can be easily held at a slightly different prompt.
Winners: Two Chatgpt models are linked to victory thanks to the lack of arithmetic mistakes.
Declare the winner
I would like to declare a clear winner in the battle of Brewing AI here, but the results are too scattered. Deepseek’s R1 model is definitely outstanding, giving a high -quality creative writing on his father’s jokes and Abraham Linka rinkan basketball prompts by quoting trusted information sources. Ta. However, the model failed with a hidden code, set a prompt with complex numbers, and created a basic error in the count and/or arithmetic that one or both of the Openai model.
However, as a whole, we are convinced that DeepSeek’s R1 models can generate overall competitive results as Openai’s best paid models. This was the only way to compete with the most established company in the world of AI, which was supposed to give a major suspension to those who undertaken extreme scaling in terms of training and calculation costs.