


Quantization is a key technique in deep learning to reduce computational costs and improve model efficiency. Large language models require significant processing power. This makes quantization essential to minimize memory usage and increase inference speed. Quantization reduces storage requirements by converting high-precision weights to low-bit formats such as INT8, INT4, or INT2. However, standard techniques often reduce accuracy, especially at low accuracy such as INT2. Researchers should either compromise accuracy for efficiency or maintain multiple models with different quantization levels. New strategies are strongly needed to maintain model quality while optimizing computational efficiency.
The fundamental problem with quantization is precisely dealing with precision reductions. Previously available approaches should train a unique model for each accuracy or not take advantage of the hierarchy of integer data types. As with INT2, quantization accuracy loss is the most difficult as it prevents its memory from being used extensively. LLMs such as the Gemma-2 9b and Mistral 7b are highly computationally intensive, and techniques that allow a single model to operate at multiple levels of accuracy will greatly improve efficiency. The need for high-performance, flexible quantization methods has led researchers to seek solutions other than traditional methods.
There are several quantization techniques, each with a balanced accuracy and efficiency. Training-free methods such as Minmax and GPTQ use statistical scaling to reduce the bit width to map the weights of the model without changing the parameters, but lose accuracy with low accuracy. Training-based methods such as using Quantization Aware Training (QAT) and overview gradient descent to optimize quantization parameters. Updated model parameters in QAT reduce model parameters to reduce loss of accuracy after quantification, but hydrogen-free learns to scale and shift parameters without changing the weights of the core. However, both methods require separate models for different accuracy, complicating deployment.
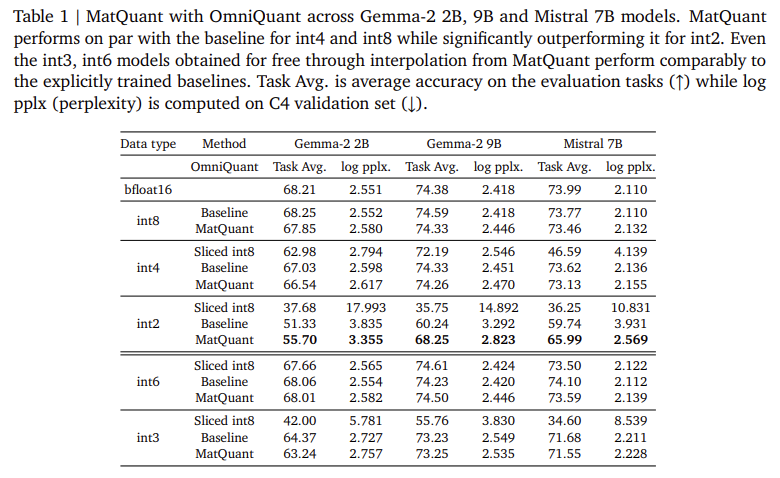
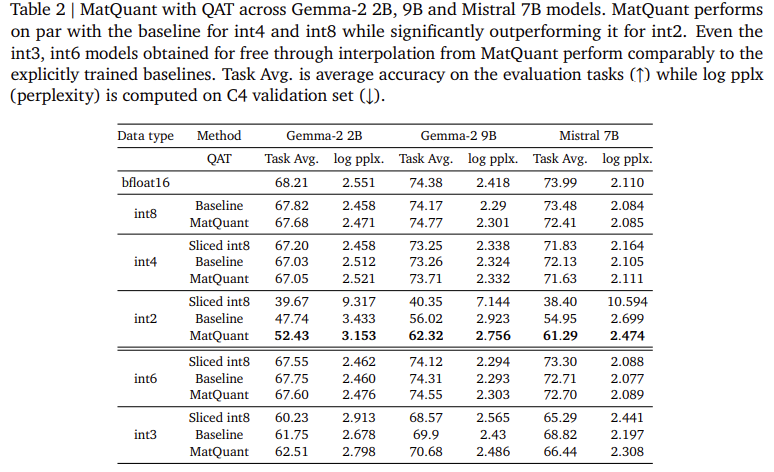
Researchers at Google Deepmind introduced Matryoshka Quantization (Matquant) to create a single model that works with multiple levels of accuracy. Unlike traditional methods of dealing with each bit width individually, Matquant uses shared bit representations to optimize INT8, INT4, and INT2 models. This allows you to deploy the model with different accuracy without retraining, reducing computational and storage costs. Matquant extracts low-bit models from high-bit models while maintaining accuracy by leveraging a hierarchical structure of integer data types. Testing on Gemma-2 2b, Gemma-2 9b, and Mistral 7b models showed that Matquant improves INT2 accuracy by up to 10% over standard quantization techniques such as QAT and Omniquant.
Matquant uses the most significant bits shared (MSB) to represent the weights of the model at different accuracy levels and jointly optimize them to maintain accuracy. The training process incorporates co-training and co-distillation to ensure that the INT2 representation holds important information that is usually lost in normal quantization. Instead of discarding low-bit structures, Matquant integrates them into a multi-scale optimization framework for efficient compression without compromising performance.
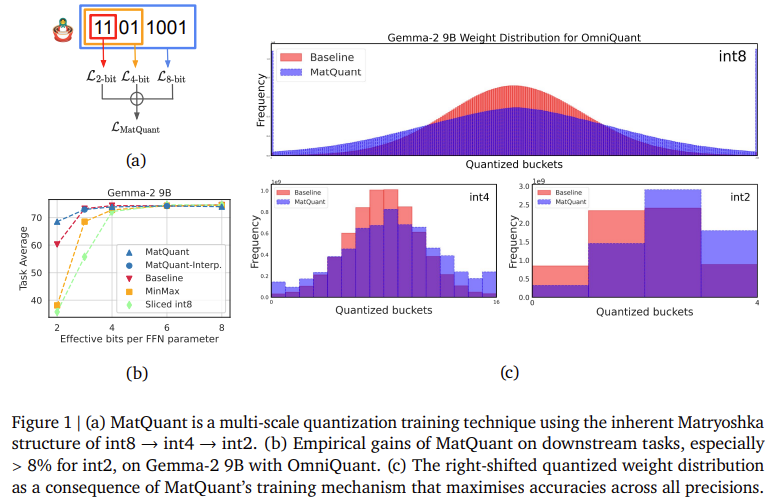
The experimental evaluation of Matquant demonstrates its ability to reduce the accuracy loss due to quantization. Researchers tested transformer-based LLMS methods and focused on quantization of feedforward network (FFN) parameters, a key factor in inference latency. The results show that Matquant’s INT8 and INT4 models achieve accuracy comparable to independently trained baselines, while surpassing them with INT2 accuracy. In the Gemma-2 9B model, Matquant improved the accuracy of Int2 by 8.01%, while the Mistral 7b model showed a 6.35% improvement over traditional quantization methods. This study also found that Matquant’s right-shifted quantum weight distribution increases accuracy across all bit widths, particularly benefiting low-precision models. Matquant also allows seamless bit-width interpolation and layer-by-layer mix’n’match configuration, allowing for flexible deployment based on hardware constraints.
Several important points emerge from Matquant’s research:
Multiscale quantization: Matquant introduces a new approach to quantization by training a single model that can operate at multiple levels of accuracy (e.g. INT8, INT4, INT2). Exploitation of nested bit structures: This technique can utilize the unique nested structures within integer data types to derive smaller bit-width integers from larger ones. Enhanced Low Precision Accuracy: MATQuant significantly improves the accuracy of INT2 quantization models, up to 8% more than traditional quantization methods such as QAT and Onmiquant. Versatile Applications: Matquant is compatible with existing learning-based quantization technologies such as Quantization Aware Training (QAT) and Omniquant. Proven Performance: This method was successfully applied to quantize FFN parameters of LLMs such as Gemma-2 2b, 9b, and Mistral 7b, and introduced practical utilities. Improved efficiency: Matquant allows for the creation of models that provide a better trade-off between accuracy and computational cost, making it ideal for resource-constrained environments. Pareto Optimal Tradeoff: By enabling seamless extraction of mutual bit widths such as INT6 and INT3 and enabling layer width mix, we allow dense accuracy VS-COST Pareto Optimal Tradeoff. Different accuracy.
In conclusion, Matquant presents a solution for managing multiple quantization models by utilizing a multi-scale training approach that utilizes nested structures of integer data types. This provides flexible, high performance options for low-bit quantization in efficient LLM inference. This study shows that a single model can be trained to operate at multiple accuracy levels, especially without significantly decreasing it at very low bit widths.
Check out the paper. All credits for this study will be sent to researchers in this project. Also, feel free to follow us on Twitter. Don’t forget to join 75K+ ML SubredDit.
Commended open source AI platform recommended: “Intelagent is an open source multiagent framework for evaluating complex conversational AI systems” (promotion)
Asif Razzaq is CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, ASIF is committed to leveraging the possibilities of artificial intelligence for social benefits. His latest efforts are the launch of MarkTechPost, an artificial intelligence media platform. This is distinguished by its detailed coverage of machine learning and deep learning news, and is easy to understand by a technically sound and wide audience. The platform has over 2 million views each month, indicating its popularity among viewers.
✅ (Recommended) Join the Telegram Channel