


I think that’s everything Andrei Carpathy Share x or YouTube It’s a gold mine of information and his latest video. Dive deep into LLMS like chatgptno exception. It provides a detailed breakdown of the important mechanisms behind LLMS. It’s a whopping 3 hours and 30 minutes and it covers a lot of ground, so I highly recommend watching it. However, if you haven’t been watching because it’s too long, there’s a TL;DW version.
LLM is trained in two major stages. Pre-training (learning from a vast dataset) and post-training (fine-tuning with human feedback).
Before training, it includes “downloading and processing the internet.” It uses datasets such as FineWeb (44TB, 15 trillion tokens) from Face.
Improve the post-training model It features reinforced learning with monitored fine-tuning (SFT) and human feedback (RLHF).
LLM suffers from hallucinations However, mitigation includes model interrogation, web search integration, and structured inference techniques.
Fast engineering plays a key role Optimizing LLM output and in-context learning allows adaptation without retraining.
LLM still has its challenges Improvements are ongoing, like fighting counts, spells, and vulnerabilities in certain scenarios.
The journey to building LLM begins with pre-training on a large text dataset. Karpathy effectively describes this step as “downloading and preprocessing the internet.” Large datasets such as embracing FineWeb (44TB, 15 trillion tokens) play an important role in training the model, predicting the next word in a sentence.
Key pre-requisite processes include:

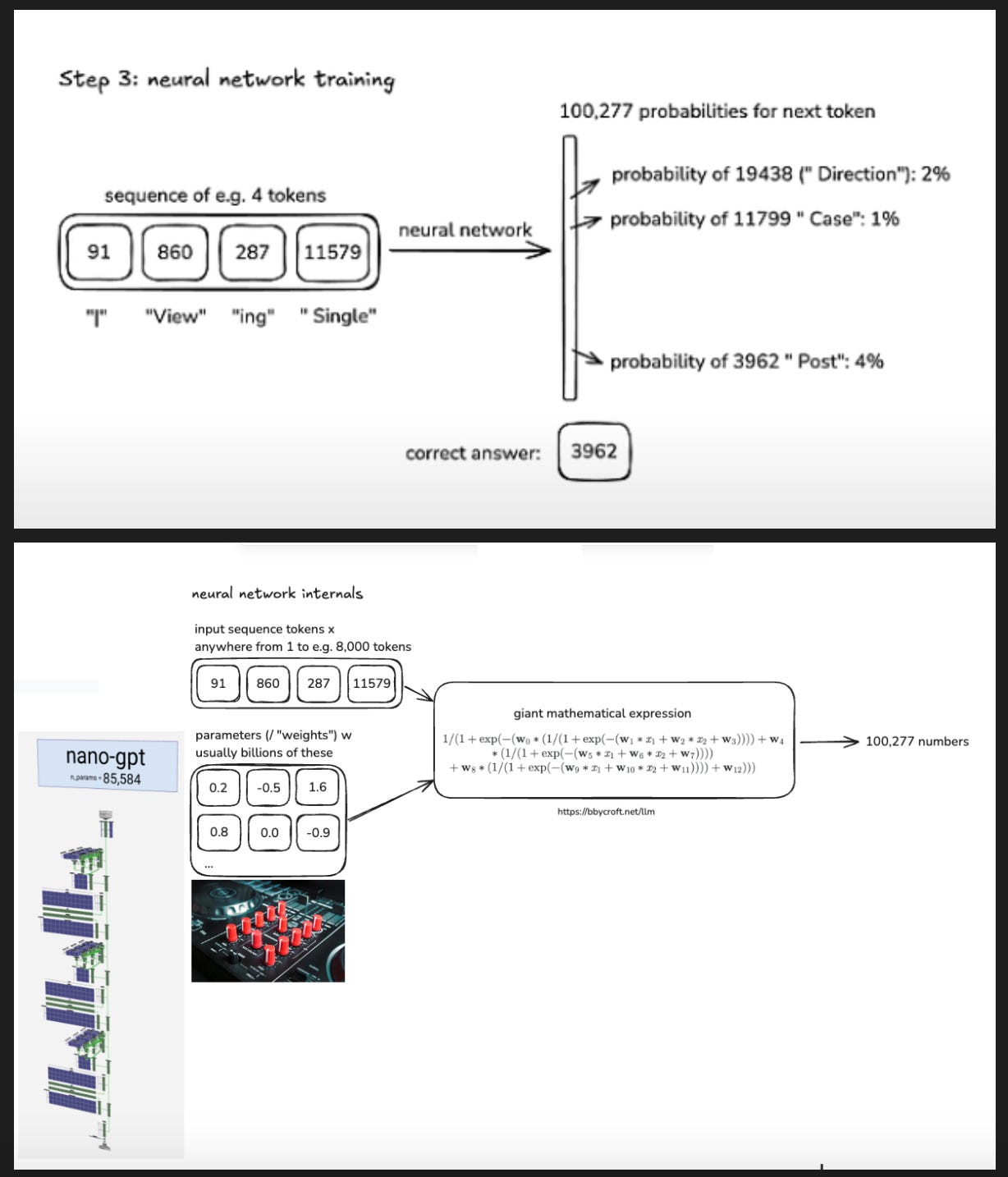
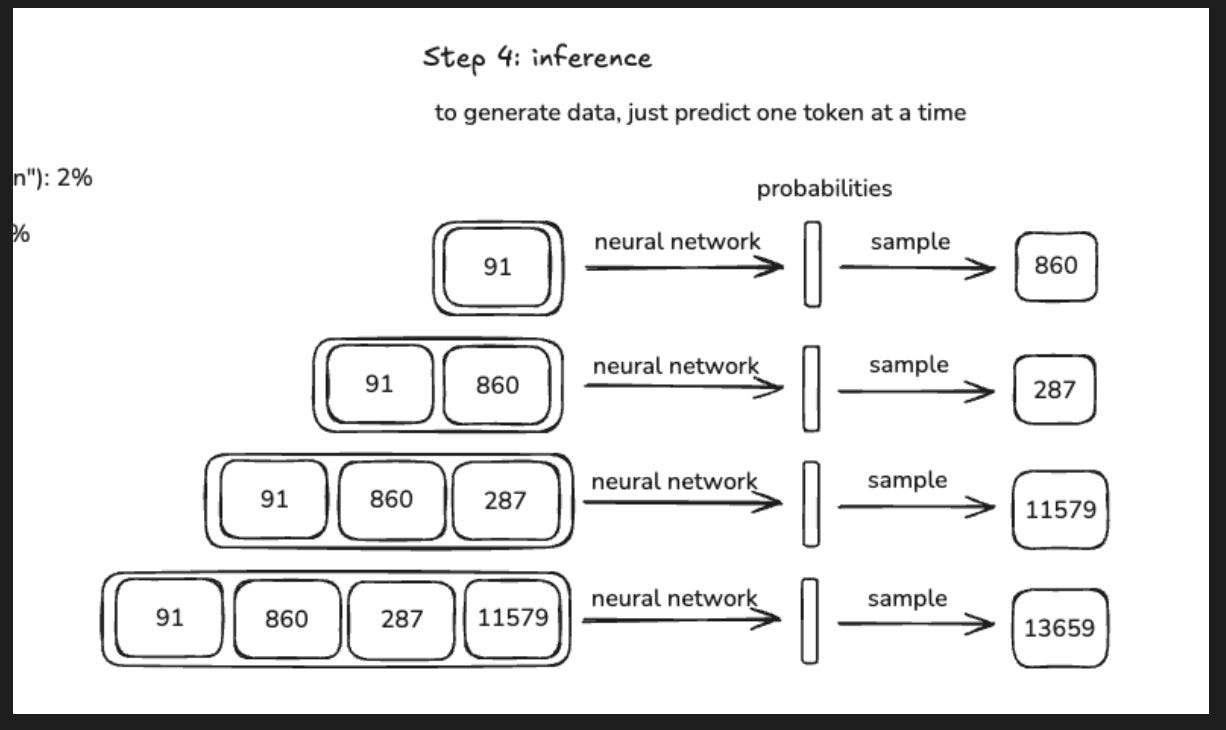
However, the base model at this stage is basically an “Internet Document Simulator.” Next, we’ll predict the next token, but it’s not optimized for useful conversations.
As explained here, I really like the idea of ”Psychology of Basic Models.”

Once the base model is trained, two important steps are performed after training.


Reinforcement learning through human feedback (RLHF): Karpathy compares this stage to a student practicing the student’s problems after learning theory. RLHF helps shape the behavior of the model, more consistent with human preferences, reduces adverse reactions and improves consistency.


A key issue with LLMS is hallucination. Here, the model confidently generates incorrect or meaningless information. Karpathy highlights the following mitigation techniques:
Model Interrogation – Teach a model for recognizing knowledge gaps.
Using tools and web search – Allows LLMS to query external sources to verify facts.
Encourage reasoning – Ask the model to “think step by step” before answering complex questions.
Karpathy is divided into rapid engineering and explains how structured prompts can greatly improve the output of the model. He also discusses in-context learning, where LLMS learns from the structure of the prompt without the need for weight adjustment.
Despite their incredible abilities, Karpathy acknowledges that LLM still faces fundamental limitations such as:
I’m struggling with counting and spelling.
The brittleness of a specific use case (Swiss cheese model of ability).
The challenge of extending structured reasoning into open-ended, creative tasks.
However, this field is moving rapidly, and simply scratching the surface of what is possible with AI-driven reasoning and problem solving.
I don’t think LLM has been compared to Swiss cheese before (or at least I’ve never come across this analogy), but I like it.

Karpathy’s presentations provide a non-technical, clear, and engaging depth about how LLM is trained, tweaked and improved. Whether you’re interested in building AI applications, understand AI tuning, or are fascinated by the internal mechanisms of CHATGPT, this talk is an essential watch.